
3 Algorithmes de DeepLearning expliqués en Langage Humain

L'apprentissage “profond” ou “deep learning” fait beaucoup parler de lui ces dernières années. Et pour cause, ce sous ensemble de l'apprentissage machine ('machine learning'') s'est imposé de manière impressionnante dans plusieurs champs de recherche: reconnaissance faciale, synthèse vocale, traduction automatique, et bien d'autres.
Ces champs de recherche ont pour point commun d'être des problèmes perceptifs, liés à nos sens et à notre expression. Ils ont ainsi representé pendant longtemps un veritable défi pour les chercheurs car il est extrêmement difficile de traduire la vue ou la voix aux moyens d'algorithmes et de formules mathématiques.
Il en résulte que les premiers modèles qui ont été mis en place dans ces domaines ont été construits à partir d'une certaine expertise métier (pour la reconnaissance vocale: la décomposition en phonèmes, pour la traduction machine: le passage par des règles grammaticales et syntaxiques). Des années de recherche ont été consacrées à l'exploitation et à la transformation de ces données non structurées de manière à en tirer du sens.
Le problème est que ces nouvelles représentaitons des données inventés par les chercheurs se sont heurtés à la généralisation: à tout texte, image ou son. Si vous avez utilisé Google Tranlate avant 2014, année à laquelle ils ont basculé à 100% sur de l'apprentissage profond, vous vous souviendrez des limites évidentes à l'époque.
L'apprentissage profond propose de se placer directement au niveau des données sans déformation ou aggrégation préalable. Puis, au moyen d'un nombre extrêmement grand de paramètres qui s'auto-ajustent au fil de l'apprentissage, le réseau va apprendre de lui même les liens implicites qui existent dans les données.
Avant de rentrer dans le détail de trois différents algorithmes* utilisés en apprentissage profond pour différents cas d'usage, commencons par définir simplement le modèle au coeur de l'apprentissage profond: le “réseau de neurones”.
*On parle également d'architectures différente de réseaux.
1. Les Réseaux de Neurones
Disons le tout de suite les réseaux de neurones n'ont que très peu à voir avec le système neuronal et le cerveau. L'analogie entre un neurone et un réseau de neurones à une couche est essentiellement graphique, dans la mesure où il y a un flux d'information d'un bout à l'autre du réseau.
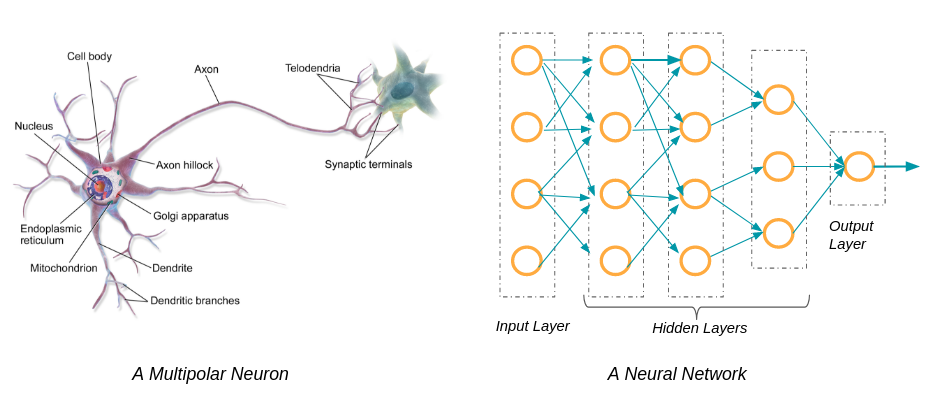 La première couche d'un réseau de neurones est celle d'entrée (input). C'est par cette couche que vont rentrer les données dont vous disposez. Avant de pouvoir “nourrir” le réseau, il faudra préalablement transformer vos données en nombres si elles n'en sont pas déjà.
La première couche d'un réseau de neurones est celle d'entrée (input). C'est par cette couche que vont rentrer les données dont vous disposez. Avant de pouvoir “nourrir” le réseau, il faudra préalablement transformer vos données en nombres si elles n'en sont pas déjà.
Nous allons prendre l'exemple de l'analyse de sentiment d'un texte.
Vous avez 10 000 commentaires sur votre site à propos de produits vendus:
Avec votre équipe vous avez labellisé 1000 d'entre eux (nous allons voir que vous pouvez également vous appuyer sur des réseaux de neurones pré-entraînés) en 3 classes (satisfait | neutre | insatisfait). Ce nombre de 3 classes, souvent utilisé dans l'analyse de sentiment, est un exemple et vous pouvez en réalité en définir plus.
- “J'ai adoré, très bon goût”;
- “Je n'ai pas beaucoup aimé l'emballage”;
- “J'ai trouvé ça plutôt bon”
La couche finale, dite de sortie (output), va vous fournir la classification “satisfait / neutre / insatisfait”.
Et toutes les couches entre la couche d'entrée et de sortie, des couches dites “cachées”, sont autant de représentations différentes des données. Par représentation cela peut être le nombre de mots dans une phrase, le nombre de ponctuations (?!) dans une phrase, etc. Vous n'aurez pas à préciser au réseau ces représentations; si statistiquement celles-ci aident à classifier correctement les phrases le réseau les apprendra tout seul.
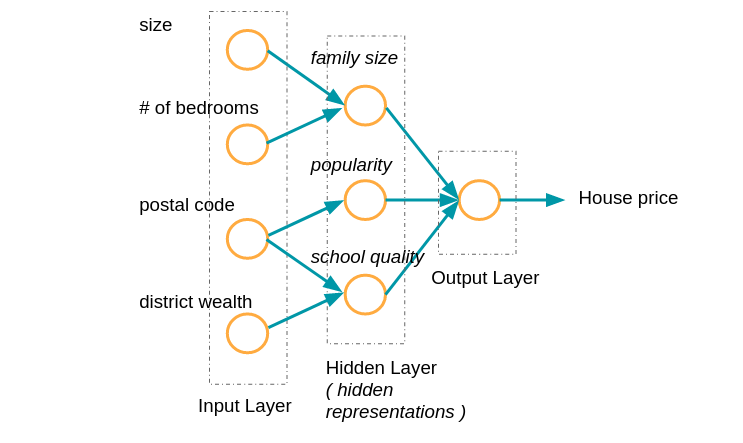
Pour illustrer ces couches prenons un autre exemple: celui de l'estimation du prix d'une maison.
Comme nous pouvons le voir on prend ici 4 variables en entrée: la superficie de la maison, le nombre de chambres, le code postal et le degré de richesse du quartier. En sortie on cherche non plus à classifier mais à prédire un nombre: le prix de la maison. C'est un problème dit de regression.
Les mots en italique renvoient à des exemples de représentations que le réseau de neurones va faire des données après en avoir vu un grand nombre.
Les paramètres du réseau sont mis à jour grâce à un processus appelé "rétropropagation". Plus il y a de couches cachées dans le réseau, plus on dit qu'il est "profond", d'où le nom d'apprentissage "profond".
Voyons maintenant 3 types architectures différents de réseaux de neurone.
2. Les réseaux de neurones dits convolutifs (CNN)
Ces réseaux sont utilisés pour tout usage autour de l'image ou de la vidéo dont fait partie la reconnaissance faciale ou encore la classification d'image.
L'entreprise Bai Du (l'équivalent de Google en Chine) a par exemple mis en place des portiques actionnés par la reconnaissance visuelle qui laissent passer uniquement leurs employés.
Snapchat et de nombreuses applications mobiles ont utilisé la percée de l'apprentissage et des CNN pour augmenter leurs fonctionnalités de “filtres”.
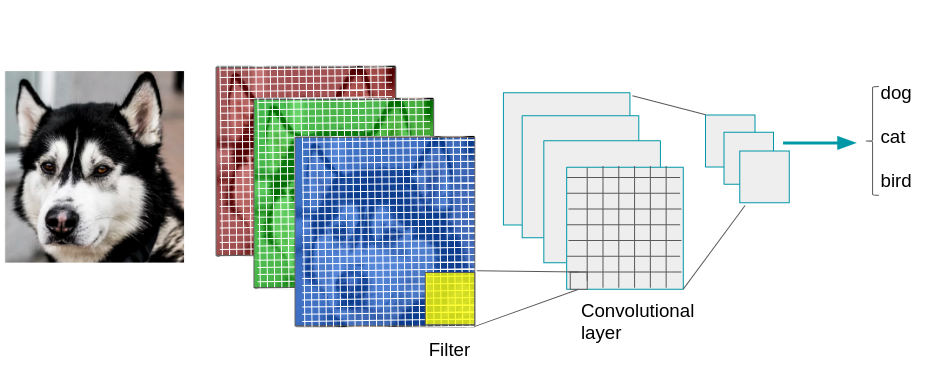 Le nom réseau convolutif renvoit à un terme mathématique: le produit de convolution.
Le nom réseau convolutif renvoit à un terme mathématique: le produit de convolution.
En termes simples, l'idée est qu'on applique un filtre à l'image d'entrée, les paramètres du filtre seront appris au fur et à mesure de l'apprentissage. Un filtre appris permettra par exemple de détecter les angles dans une image si les angles servent à classifier au mieux l'image.
L'image est d'abord décomposé dans les 3 cannaux (R,G,B) pixels par pixels, on obtient donc 3 matrices de taille n x n (où n est le nombre de pixels).
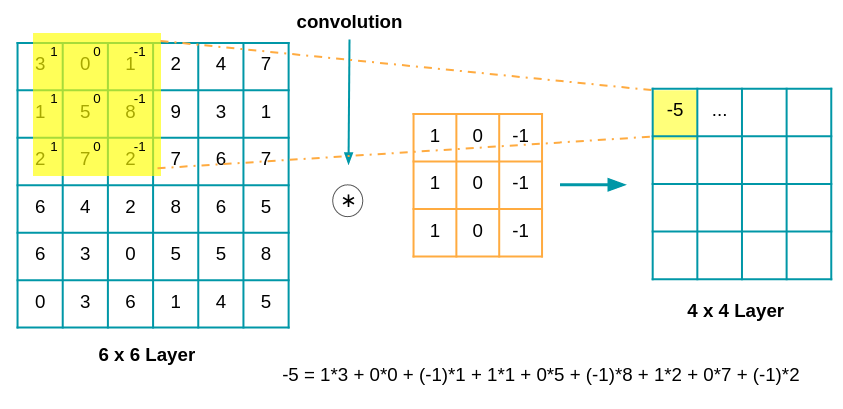
Voici un exemple de convolution avec une matrice de taille 6 x 6 :
:
Il est important de noter deux avantages importants inhérents aux réseaux convolutifs :
- le réseau peut apprendre par étape à reconnaitre les éléments caractéristiques d'une image. Pour reconnaître un visage par exemple: il apprendra à reconnaître d'abord des paupières, des pupilles, pour arriver à identifier des yeux;
- une fois un élément appris à un endroit de l'image le réseau sera capable de le reconnaître n'importe où d'autre dans l'image.
3. Les réseaux de neurones dits récurrents (RNN)
Les réseaux de neurones récurrents sont au coeur de bon nombre d'améliorations substantiels dans des domaines aussi divers que la reconnaissance vocale, la composition automatique de musique, l'analyse de sentiments, l'analyse de séquence ADN, la traduction automatique.
La différence principal avec les autres réseaux de neurones vient du fait que ces derniers tiennent compte de l'enchaînement successif des données, bien souvent de leur enchaînement dans le temps. Par exemple dans le cas de l'analyse d'une série de mesures de capteurs (séries temporelles) le réseau aura encore en mémoire tout ou partie des observations précédentes.
Le schéma de ce réseau est produit ici:
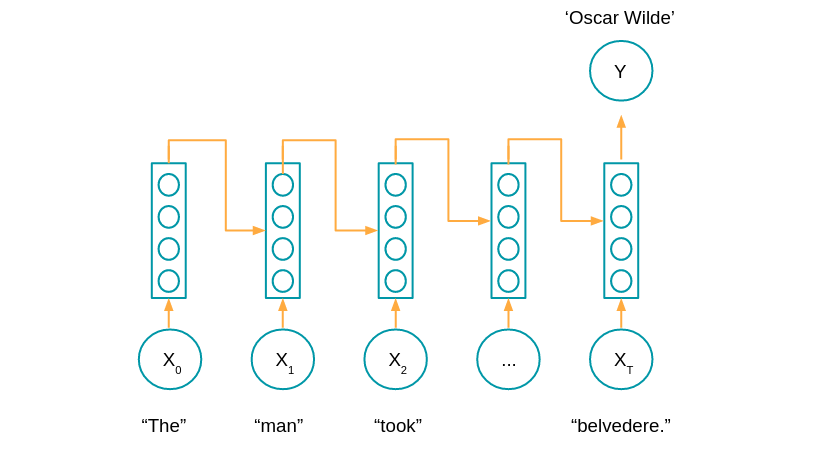
Au lieu de prendre en compte les données d'entrée de manière séparée (comme un CNN analyse image par image) le réseau récurrent lui prend en compte les données d'entrée passées.
Certaines architectures, dites bidirectionnelles, peuvent aussi prendre en compte les données futures. Par exemple lors d'une analyse de texte où on cherche à trouver des entités nommées (noms de personnes, sociétés, pays, etc.) nécessite de voir les mots de toute la phrase.
Exemple:
- “Je vois que [Jean] Valjean t'as encore échappé, Javert!”
- “Je vois que [Jean] R. joue également dans l'adaptation des Misérables.”
Le début de phrase ne suffit pas à identifier qui est “Jean”.
4. Les Auto encodeurs
Les auto encodeurs sont appliqués principalement à la détection d'anomalie ( par exemple pour détecter la fraude en banque ou bien pour trouver des anomalies dans une ligne de production industrielle ). Ils peuvent également servir à la réduction de dimension (proche dans l'idée d'une Analyse en Composante Principale). En effet le but des auto encodeurs est d'apprendre à la machine en quoi consiste des observations “normales”.
L'architecture de notre réseau est le suivant:
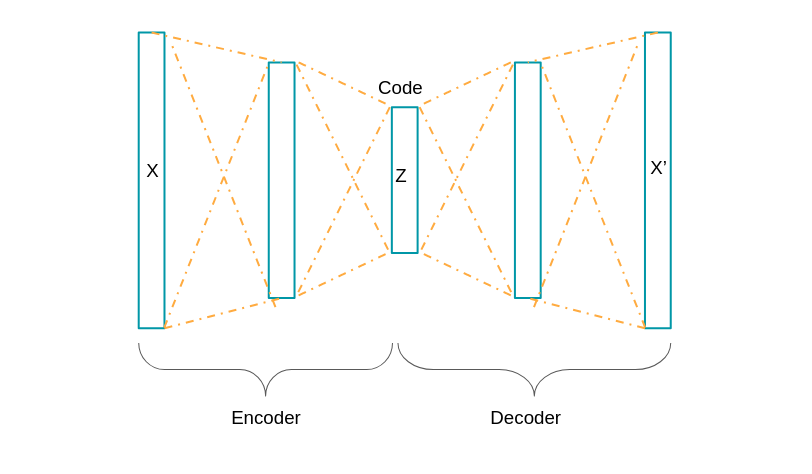
Le réseau va donc représenter les données au moyen d'une ou plusieurs couches cachées de sorte à ce qu'en sortie on retrouve les mêmes données qu'en entrée.
L'objectif de retrouver en sortie les memes données qu'en entrée est caractéristique des auto-encodeurs (analogue à la fonction identité f(x)=x).
La phase d'encodage et de décodage n'est elle pas propre aux auto-encodeurs. En effet, on les retrouve dans la traduction automatique dans des réseaux de neurones récurrents.
Après avoir entraîné le réseau avec suffisamment de données il sera possible d'identifier des observations suspectes ou anormales lorsque celles-ci dépassent un certain seuil par rapport à la nouvelle “norme”.
Conclusion:
Nous avons vu 3 grands types de réseau de neurones :
- les réseaux convolutifs avec des applications dans la reconnaissance faciale et classification d'images
- les réseaux récurrents avec des applications dans l'analyse du texte et de la voix;
- les auto encodeurs avec des applications à la détection d'anomalie et à la réduction de dimension
D'autres architectures existent comme les GAN, réseaux antagonistes génératifs, qui sont composés d'un modèle générant des candidats pour une tache donnée, par exemple synthétiser une image, et d'un autre qui les évaluent. Ou encore l'apprentissage par renforcement, méthode utilisée par DeepMind pour entrainer leurs modèles Alpha Go et Alpha Go zéro.
Bien évidemment des limites existent: par exemple il est possible de tromper des réseaux convolutifs en ajoutant un bruit particulier à des images non détectable à l'oeil humain mais qui peut etre fatal pour un modèle qui n'a pas été assez testé en robustesse. De nouvelles architectures telles que les réseaux de capsules ont fusionné pour faire face à ce problème particulier.

Il est certain que l'apprentissage profond a encore de beaux jours devant lui avec de nombreuses nouvelles applications pour les entreprises à venir.
Gaël Bonnardot,
Cofounder et CTO chez Datakeen
Chez Datakeen nous cherchons à simplifier l'utilisation et la compréhension des nouveaux paradigmes d'apprentissage automatique par les fonctions métier de toutes les industries.
Contact us for more information: contact@datakeen.co
Continuer la lecture



{kind=link}
Prêt à en voir plus ?
Une nouvelle façon de gérer la vérification d’identité, plus simple et plus sûre.
