

“Deep” Learning has attracted much attention during these past years. And for a good reason: this subset of machine learning has stood out impressively in several research fields: facial recognition, speech synthesis, machine translation, and many others.
These research fields have in common to be perceptual problems related to our senses and our expression. They have long represented a real challenge for researchers because it is extremely difficult to model vision or voice by means of algorithms and mathematical formulas.
As a result, the first models that have been implemented in these fields have been constructed with a good deal of business expertise (in speech recognition: decomposition into phonemes, in machine translation: application of grammatical and syntactic rules). Years of research have been dedicated to the exploitation and processing of these non-structured data in order to derive meaning.
The problem is that these new representations of data invented by researchers have failed to generalize at full extent to any text, sound or image. If you used Google Translate before 2014, year when they switched to a 100% deep learning model, you will remember the obvious limitations at the time.
Deep learning places itself directly on top of raw data without distortion or pre-aggregation. Then, thanks to a very large number of parameters that self-adjust over learning, will learn from implicit links existing in the data.
Before going into details of three different algorithms * used in deep learning for different use cases, let’s start by simply defining the model at the heart of deep learning: the “neural network”.
* We also talk about different network architectures.
1. Neural networks
Let me begin by saying that neural networks have very little to do with the neural system and the brain. The analogy between a neuron and a one-neuron neural network is essentially graphic, insofar as there is a flow of information from one end to the other network.

The first layer of a neural network is called the input layer. It is through this layer that your data will enter the network. Prior to “feeding” the network with your data you will need to change it to numbers if they are not already.
We’ll take the example of sentiment analysis on textual data.
Let’s say you have 10,000 comments on your ecommerce website about products sold:
With your team you have labeled 1000 of them (we’ll see that you can also rely on pre-trained neural networks) into 3 classes (satisfied | neutral | dissatisfied). This number of 3 classes, often taken in the sense of analysis, is an example and you can actually set more.
– “I loved it, very good taste”;
– “I didn’t like the packaging that much”;
– “I thought it was pretty good”
The final layer, called output layer, will provide you with the classification “satisfied / neutral / dissatisfied”.
And all layers between the input and output layer, layers called “hidden” are all different representations of the data. A representation may be the number of words in a sentence, the number of punctuation (?!) in a sentence, etc. You will not have to specify the network these representations; if statistically they help to correctly classify the sentences the network will teach alone.

To illustrate these layers take another example: that of the estimated price of a home.
As we can see here we take four input variables: the size of the house, number of bedrooms, the postal code and the degree of richness of the area. The output is not seeking to classify but to predict a number: the price of the house. This is a problem known as regression.
The italicized words to examples of representations that the neural network will make the data after having seen many.
The parameters of the network are updated thanks to a process called “backpropagation”. And the more hidden layers there are in the network the “deeper” it is, hence the name “Deep” Learning.
Let us now see 3 different types of architectures of neural networks.
2. Convolutional Neural Networks (CNN)
These networks are used for all use cases around image or video which include face recognition or image classification.
For example Bai Du (the equivalent of Google in China) has set up portals powered by face recognition to let enter only employees of the company.
Snapchat and many mobile applications have leveraged the breakthroughs of deep learning and CNNs to increase their face recognition capacities in order to add extra layers on your face such as funny bunny ears and a pink nose.

The name “convolution” comes from a mathematical operation: convolution between functions.
Put simply, the convolution applies a filter to the input image, the filter parameters are learned through the learning. A learnt filter will be able of detecting features in an image, for example angles, and use them to classify at best the image.
The image is first decomposed into 3 channels (R, G, B) pixels per pixel, we obtain three matrices of size n x n (where n is the number of pixels).
Below is an example of a convolution with a 6 x 6 size matrix:

It is important to note two important advantages inherent to convolutional networks:
- the network can learn by steps to recognize characteristics in an image. To recognize a face for instance: it will learn to recognize first of eyelids and pupils, and then recognize eyes;
- once an item to a learned image place the network will be able to recognize it anywhere else in the picture.
3. Recurrent neural networks (RNN)
Recurrent neural networks are at the heart of many substantial improvements in areas as diverse as speech recognition, automatic music composition, sentiment analysis, DNA sequence analysis, machine translation.
The main difference with other neural networks is that they take into account a sequence of data, often a sequence evolving over time. For example in the case of analyzing temporal data (time series) the network will still have in memory a part or all of the observations previous to the data being analyzed.
The pattern of this network is produced here:

Instead of taking into account separately input data (in the way a CNN would analyse image per image) the recurrent network takes into account data previously processed.
Some architectures, called bidirectional, can also take into account future data. For instance when analyzing text to identify named entities (people, companies, countries, etc.) the network would need to see the words of the whole sentence.
Example:
- “I see [Jean] Valjean still have escaped you, Javert!”
- “I see [Jean] R. plays in this adaptation of ‘Les Misérables’”.
The beginning of the sentence (underlined) is not enough to identify who is ‘Jean’.
4. Autoencoders
Autoencoders are applied mainly to anomaly detection (for example to detect fraud in banking or to find faults in an industrial production line). They can also be used in dimensionality reduction (close to the objective of a Principal Component Analysis). Indeed the goal of autoencoders is to teach the machine what constitutes “normal” data.
The architecture of our network is the following:
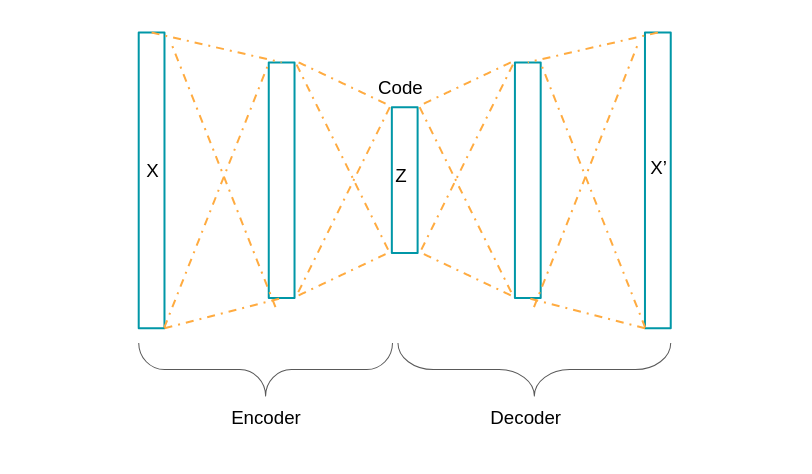
The network will therefore represent data through one or more hidden layers so that the output will be as close as possible to the input data.
The objective to find the same data back as the output of the network is characteristic of autoencoders (analogous to the identity function f (x) = x).
The encoding and decoding stage it is not however specific to autoencoders. Indeed, they are found in machine translation in recurrent neural networks.
After training the network with enough data it will be possible to identify suspicious or anomalous observations when they exceed a certain threshold compared to the new “standard”.
Conclusion:
We saw 3 major types of neural networks:
- Convolution networks with applications in facial recognition and image classification;
- Recurrent networks with applications in the timeseries, text and voice analysis;
- Autoencoders with applications to anomaly detection as well as dimensionality reduction.
Other architectures exist such as GANs, generative adversarial networks, which are composed of a model generating candidates for a given task, for example image creation, and another that evaluates the different outputs. Or Reinforcement Learning, a method used by Deepmind to train their Alpha Go and Alpha Go Zero models.
Obviously there are limits: for example it is possible to fool convolutional network by adding a particular sound to image undetectable to the human eye but can be fatal for a model that has not been sufficiently tested robustness. New architectures such as capsule networks have merged to face this particular problem.

All in all it is certain that deep learning has a bright future with many business applications to come.
Gaël Bonnardot,
Cofounder and CTO at Datakeen
At Datakeen we seek to simplify the use and understanding of new machine learning paradigms by the business functions of all industries.
Contact us for more information: contact@datakeen.co
